URL Loading
Deprecation of the technologies described here has been announced for platforms other than ChromeOS.
Please visit our migration guide for details.
Introduction
This section describes how to use the URLLoader API to load resources such as images and sound files from a server into your application.
The example discussed in this section is included in the SDK in the directory examples/api/url_loader.
Reference information
For reference information related to loading data from URLs, see the following documentation:
- url_loader.h - Contains
URLLoaderclass for loading data from URLs - url_request_info.h - Contains
URLRequestclass for creating and manipulating URL requests - url_response_info.h - Contains
URLResponseclass for examaning URL responses
Background
When a user launches your Native Client web application, Chrome downloads and caches your application’s HTML file, manifest file (.nmf), and Native Client module (.pexe or .nexe). If your application needs additional assets, such as images and sound files, it must explicitly load those assets. You can use the Pepper APIs described in this section to load assets from a URL into your application.
After you’ve loaded assets into your application, Chrome will cache those assets. To avoid being at the whim of the Chrome cache, however, you may want to use the Pepper FileIO API to write those assets to a persistent, sandboxed location on the user’s file system.
The url_loader example
The SDK includes an example called url_loader demonstrating downloading files from a server. This example has these primary files:
index.html- The HTML code that launches the Native Client module.example.js- The JavaScript file for index.html. It has code that sends a PostMessage request to the Native Client module when the “Get URL” button is clicked.url_loader_success.html- An HTML file on the server whose contents are being retrieved using theURLLoaderAPI.url_loader.cc- The code that sets up and provides and entry point into the Native client module.url_loader_handler.cc- The code that retrieves the contents of the url_loader_success.html file and returns the results (this is where the bulk of the work is done).
The remainder of this document covers the code in the url_loader.cc and url_loader_handler.cc files.
URL loading overview
Like many Pepper APIs, the URLLoader API includes a set of methods that execute asynchronously and that invoke callback functions in your Native Client module. The high-level flow for the url_loader example is described below. Note that methods in the namespace pp::URLLoader are part of the Pepper URLLoader API, while the rest of the functions are part of the code in the Native Client module (specifically in the file url_loader_handler.cc). The following image shows the flow of the url_loader_handler code:
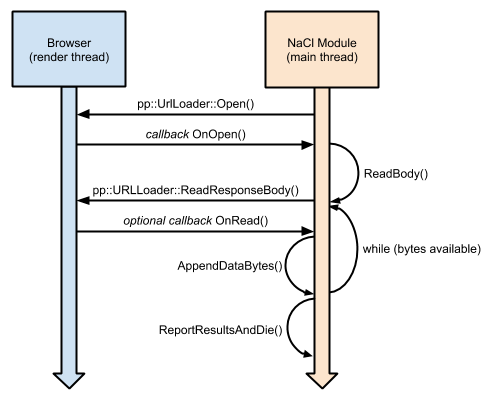
Following are the high-level steps involved in URL loading.
- The Native Client module calls
pp::URLLoader::Opento begin opening the URL. - When
Opencompletes, it invokes a callback function in the Native Client module (in this case,OnOpen). - The Native Client module calls the Pepper function
URLLoader::ReadResponseBodyto begin reading the response body with the data.ReadResponseBodyis passed an optional callback function in the Native Client module (in this case, OnRead). The callback function is an optional callback becauseReadResponseBodymay read data and return synchronously if data is available (this improves performance for large files and fast connections).
The remainder of this document demonstrates how the previous steps are implemented in the url_loader example.
url_loader deep dive
Setting up the request
HandleMessage in url_loader.cc creates a URLLoaderHandler instance and passes it the URL of the asset to be retrieved. Then HandleMessage calls Start to start retrieving the asset from the server:
void URLLoaderInstance::HandleMessage(const pp::Var& var_message) {
if (!var_message.is_string()) {
return;
}
std::string message = var_message.AsString();
if (message.find(kLoadUrlMethodId) == 0) {
// The argument to getUrl is everything after the first ':'.
size_t sep_pos = message.find_first_of(kMessageArgumentSeparator);
if (sep_pos != std::string::npos) {
std::string url = message.substr(sep_pos + 1);
printf("URLLoaderInstance::HandleMessage('%s', '%s')\n",
message.c_str(),
url.c_str());
fflush(stdout);
URLLoaderHandler* handler = URLLoaderHandler::Create(this, url);
if (handler != NULL) {
// Starts asynchronous download. When download is finished or when an
// error occurs, |handler| posts the results back to the browser
// vis PostMessage and self-destroys.
handler->Start();
}
}
}
}
Notice that the constructor for URLLoaderHandler in url_loader_handler.cc sets up the parameters of the URL request (using SetURL, SetMethod, and SetRecordDownloadProgress):
URLLoaderHandler::URLLoaderHandler(pp::Instance* instance,
const std::string& url)
: instance_(instance),
url_(url),
url_request_(instance),
url_loader_(instance),
buffer_(new char[READ_BUFFER_SIZE]),
cc_factory_(this) {
url_request_.SetURL(url);
url_request_.SetMethod("GET");
url_request_.SetRecordDownloadProgress(true);
}
Downloading the data
Start in url_loader_handler.cc creates a callback (cc) using a CompletionCallbackFactory. The callback is passed to Open to be called upon its completion. Open begins loading the URLRequestInfo.
void URLLoaderHandler::Start() {
pp::CompletionCallback cc =
cc_factory_.NewCallback(&URLLoaderHandler::OnOpen);
url_loader_.Open(url_request_, cc);
}
OnOpen ensures that the Open call was successful and, if so, calls GetDownloadProgress to determine the amount of data to be downloaded so it can allocate memory for the response body.
Note that the amount of data to be downloaded may be unknown, in which case GetDownloadProgress sets total_bytes_to_be_received to -1. It is not a problem if total_bytes_to_be_received is set to -1 or if GetDownloadProgress fails; in these scenarios memory for the read buffer can’t be allocated in advance and must be allocated as data is received.
Finally, OnOpen calls ReadBody.
void URLLoaderHandler::OnOpen(int32_t result) {
if (result != PP_OK) {
ReportResultAndDie(url_, "pp::URLLoader::Open() failed", false);
return;
}
int64_t bytes_received = 0;
int64_t total_bytes_to_be_received = 0;
if (url_loader_.GetDownloadProgress(&bytes_received,
&total_bytes_to_be_received)) {
if (total_bytes_to_be_received > 0) {
url_response_body_.reserve(total_bytes_to_be_received);
}
}
url_request_.SetRecordDownloadProgress(false);
ReadBody();
}
ReadBody creates another CompletionCallback (a NewOptionalCallback) and passes it to ReadResponseBody, which reads the response body, and AppendDataBytes, which appends the resulting data to the previously read data.
void URLLoaderHandler::ReadBody() {
pp::CompletionCallback cc =
cc_factory_.NewOptionalCallback(&URLLoaderHandler::OnRead);
int32_t result = PP_OK;
do {
result = url_loader_.ReadResponseBody(buffer_, READ_BUFFER_SIZE, cc);
if (result > 0) {
AppendDataBytes(buffer_, result);
}
} while (result > 0);
if (result != PP_OK_COMPLETIONPENDING) {
cc.Run(result);
}
}
void URLLoaderHandler::AppendDataBytes(const char* buffer, int32_t num_bytes) {
if (num_bytes <= 0)
return;
num_bytes = std::min(READ_BUFFER_SIZE, num_bytes);
url_response_body_.insert(
url_response_body_.end(), buffer, buffer + num_bytes);
}
Eventually either all the bytes have been read for the entire file (resulting in PP_OK or 0), all the bytes have been read for what has been downloaded, but more is to be downloaded (PP_OK_COMPLETIONPENDING or -1), or there is an error (less than -1). OnRead is called in the event of an error or PP_OK.
Displaying a result
OnRead calls ReportResultAndDie when either an error or PP_OK is returned to indicate streaming of file is complete. ReportResultAndDie then calls ReportResult, which calls PostMessage to send the result back to the HTML page.